심리적 / 사회적 요인에 따른 약물 오남용 위험도 예측
- 개인의 성격 특성, 충동성, 감각추구성향 등 데이터를 활용하여 약물 사용 여부를 자동으로 분류하는 모델을 개발
- 주어진 데이터를 바탕으로 탐색적 데이터 분석(EDA), 전처리, 모델링을 수행하여 약물 사용 위험 예측의 정확도를 최적화
- 약물 사용 위험도를 평가하고, 이를 시각적으로 표현하는 것도 중요한 목표
[바이오] 약물 사용 데이터 기반 위험도 예측 및 분류 | Notion
목차
teamsparta.notion.site
- 프로젝트 제목과 요약, 분석 방법
- 프로젝트 명 : 심리적 사회적 요인에 따른 약물 오남용 위험도 예측
- 주제 선정 이유 : 보다 다양한 조합의 해석이 가능할 것 같았기 때문입니다.
- 프로젝트 목표:
- 최근 늘어난 마약 소비에 대응하여, 약물 오남용에 취약한 심리적 요인과 환경적 요인의 특성을 파악 및 위험도를 예측하고, 예방과 조치에 대해 소개하고자 합니다.
- 분석 방법:
- 약물 사용 데이터를 기반으로 심리적 특성에 따른 약물 사용 간의 관계를 파악하고, 약물 오남용의 패턴과 빈도를 파악하기 위해 약물 사용 패턴 확인
- 최근 늘어난 청년층의 약물 오남용을 미치 예측하고 예방하기 위해 개인의 특성과 심리적 특성을 기반으로 약물 사용 위험도를 예측하는 머신러닝 모델을 구축할 예정
- 분석을 바탕으로 약물 오남용에 취약한 연령층, 환경을 분석하고 위험도를 예측하여 심리적, 사회적 변화 방안을 제시
[ 발표 구성 흐름 ]
1) 사용한 데이터 : drug_consumption.csv

2) 데이터 소개
- 사회적(개인적) 특성 - 연령, 성별, 인종, 교육 수준, 거주 국가
- 심리적 특성
3) Clustering(약물 종류 소개)
- 약물 간의 상관관계를 분석하여, 비슷한 특성을 가진 약물들을 군집으로 묶어 심층적으로 분석
- 군집 내 약물들이 심리적/사회적 요인에서 유사한 패턴이 보인다면, 특정 군집 대상 분석을 통해 약물 사용의 위험도를 더 정확하게 예측할 수 있음
- 약물 분류 결과
- Non-Usrs (미사용자) : CL0, CL1, CL2 (지난 1년 내 약물을 사용하지 않은 그룹)
- Users(사용자) : CL3, CL4, CL5, CL6 (지난 1년 내 약물을 사용한 그룹)
(4) 가설 설정
- 신경증(N), 외향성(E), 개방성(O), 충동성(Imp), 감각추구성향(SS)이 높을수록 약물 오남용 위험도가 높을 것이다.
- 친화성(A), 성실성(C) 이 낮을수록 약물 오남용 위험도가 높을 것이다.
- 연령과 교육 수준이 상대적으로 낮을수록 약물 오남용 위험도가 높을 것이다.
(5) 상관관계 분석
1) 수치형 변수였던 심리적 특성 7가지 분포 확인
- 분포 확인 결과 스코어 값들은 대부분 정규성을 띄고 있는 것 같아 보였음 (이미 스케일링 된 데이터)
2) 정규성 검정(Shapiro-Wilk Test)
- 검정 결과, Nscore을 제외하고는 거의 모두 정규성을 만족하지 못함
- 비모수 상관 분석이 가능한 스피어만(Spearman) 방법을 이용하기로 함
3) Spearman
∣ρ∣< 0.1 → 너무 약한 상관 → 제거 가능
∣ρ∣> 0.3 → 의미 있는 상관 → 유지
0.1 ≤∣ρ∣≤ 0.3 → 애매 → 다른 방법과 함께 고려
p-value가 0.05 이상이면 통계적으로 유의미하지 않으므로 제외 가능
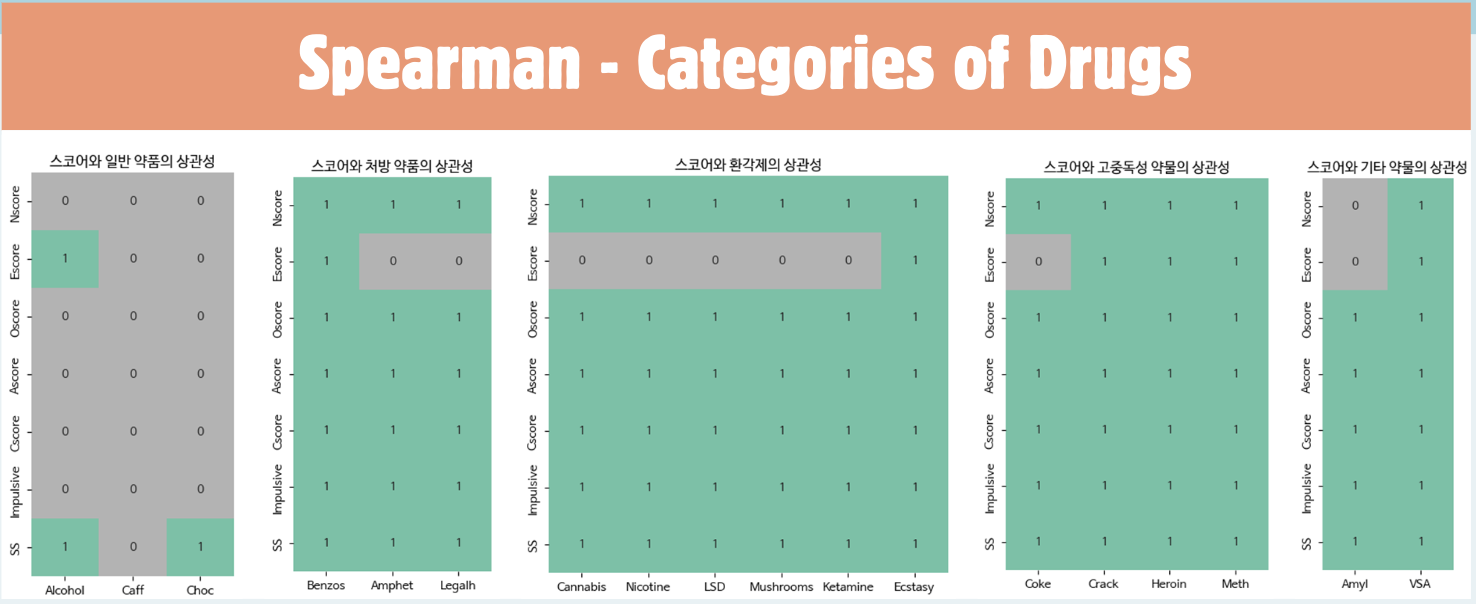

- 감각추구성향(SS), 충동성은 거의 모든 컬럼에서 유의미함 -> 이 성격 특성들은 약물 사용에 영향을 줌
- 스코어를 기준으로 나눈 분류는 처음 나눈 분류 결과와 비슷
4) 심리적 특성 - 약물 특성 (피어슨 상관계수 & Score 평균)
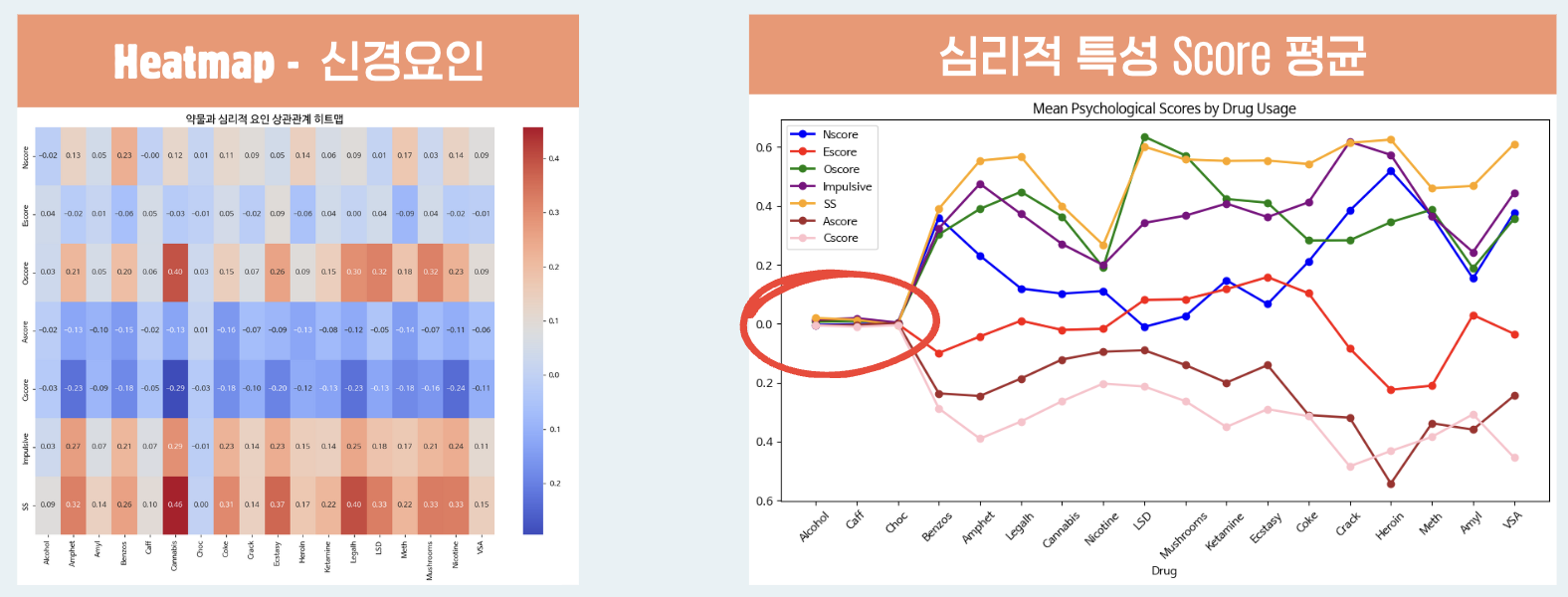
- 합법적 기호식품(Alcohol, Caff, Choc)은 심리적 특성과 관계가 없음을 알 수 있음 -> 추후 분석에서 제거
- 스코어끼리 상관관계가 있는 특성은 약물의 평균 분포와도 비슷한 흐름임
- 처음 예측했던, 가설은 상관관계를 보아 채택할 수 있을 것으로 보임
- 신경증(N), 외향성(E), 개방성(O), 충동성(Imp), 감각추구성향(SS)이 높을수록 약물 오남용 위험도가 높을 것이다.
- 친화성(A), 성실성(C) 이 낮을수록 약물 오남용 위험도가 높을 것이다.
(6) Hyper Parameter 조정
- 약물 사용자 그룹(1)과 약물 미사용자 그룹(0) 간의 불균형이 매우 심함
- 예측 정확도는 매우 높게 나오지만, 재현율은 극도로 낮게 나옴 (다수 클래스 쪽의 사용도로 예측해버림 -> 이번 경우에는 거의 0)
- 약물 사용은 사용자의 건강에 치명적인 악영향을 미치므로 위험도를 정확하게 에측하는 것이 필요
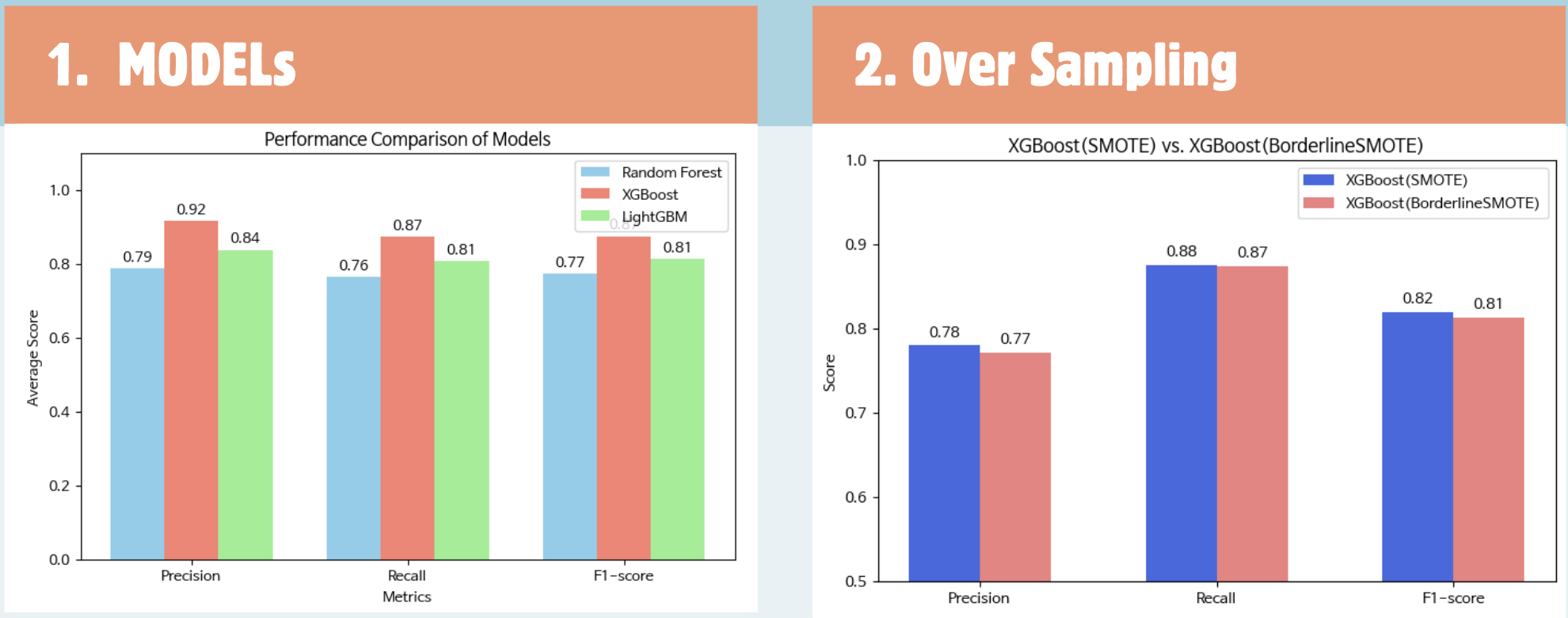
1) Over Sampling
- SMOTE : 소수 클래스에서 가상의 데이터를 생성
- BorderlineSMOTE : 경계선 부분에 대해서만 SMOTE 방식 사용
2) GridSearchCV / Threshold
- GridSearchCV : 직접 모델의 하이퍼파라미터 값을 리스트로 입력하면, 값에 대한 경우의 수마다 예측 성능을 평가하여 최적의 조합을 탐색
- Threshold : 이 값을 기준으로 그 이상이면 1이라고 예측, 0과 1의 비율 차이가 많이 날 경우 한 쪽에 무게를 둠
3) Feature Selection : 약물과 상관성이 있는 Score 값만 x 변수에 입력
- 예시로 드는 Benzos는 모든 Score가 유의미했으므로 Feature 동일하게 넣음

(7) Feature Engineering

- Sampling 만으로 이 데이터의 불균형을 처리하기에는 어려움이 있었음
- 모델의 성능을 향상시킬 수 있는 새로운 Feature를 추가하는 방법은 Feature Engineering 진행
- 이번 데이터에서 다루는 약물은 대부분 중독성이 강하고, 마약류에 속하기 때문에 단 한 가지의 약물만 사용하지는 않을 것이라는 판단을 내림
- 따라서 ID 당 사용해 본 약물 종류의 개수를 세는 컬럼
- 클러스터링 기반 약물 그룹의 사용 여부(그룹의 개수 - Coke(중독성 높은 마약류), Amyl(기타 약물), Benzos(처방약물) 을 사용해본 ID라면 3을 출력)
- 위 두 컬럼 추가로 개별 약물보다 더 다양하고 일반회된 패턴으로 모델이 학습할 수 있도록 함
- 상관분석에서 대부분의 약물이 충동성과 감각추구형에 대해 높은 상관을 보였으므로 이 둘을 가중한 수치를 출력하도록 하는 컬럼을 추가
- 같은 생각으로 신경성(N)과 충동성(Imp), 개방성(O)과 외향성(E)를 가중한 Feature 생성 (신경성이 높아 예민한 사람이 충동적으로 이를 완화하기 위해 약물을 투여했을 가능성 존재 / 개방적이고 외향적 특성을 가진 사람이 더 다양한 상황을 접하며 약물에 접촉했을 가능성 존재)
- 이후 모델을 실행했을 때, 대부분 약물에서 성능 향상을 보였으나, 일부 약물에 성능이 낮게 나옴
- 약물들의 공통점을 조사해보니 '가격이 싸고 구하기 쉬운' 약물임을 발견
- 데이터에 주어진 것으로 경제성을 평가하는 Feature를 만들기 위해 교육수준과 연령을 조절하여 3개의 컬럼을 추가
- 교육 수준에서 학위를 갖고 있지 않은 사람은 경제성이 낮을 가능성 존재 / 연령이 어린 사람은 경제력이 낮을 것이라는 가능성 / 이 두가지 조건을 만족하는 사람
(8) Machine Learning
1) Model 선택
- 여러 모델을 탐색하여 더 정확하게 예측하는 모델을 탐색
- 가장 먼저 랜덤 포레스트 모델을 사용하여 결과를 확인하였을 때 나쁘지 않은 평가 지표를 얻음
- 하지만, 저희 데이터는 불균형이 심하고 오답을 예측하는 경우가 많았기 때문에, 오답에 대해 벌점을 부과하는 부스팅 모델도 함께 비교하고자 함
- 랜덤 포레스트, XGBoost, LightGBM 3가지 모델을 같은 조건으로 실행한 결과 XGBoost의 성능이 가장 좋은 것을 확인
- 이후, 불균형 해소로 모델 최적화를 도모하기 위해 앞서 결정된 XGBoost 모델에 SMOTE와 BorderlineSMOTE를 적용
- 값은 비슷했지만 미세하게 SMOTE가 성능이 더 좋았기에 SMOTE를 이용한 XGBoost 모델을 최종 모델로 선정
(9) 실행
- 최종 결정된 모델에 맞는 하이퍼파라미터 재조정
- 기존 Sampling만 했을 때보다 정확도 63% -> 86% / 재현율 45% -> 80% 로 성능이 향상됨

(10) 과적합(Overfitting) 검정
- Train set과 Test set의 정확도(Accuracy) 비교
- Train set의 정확도가 너무 높고, Test set의 정확도가 상대적으로 낮으면 과적합 가능성 높음.
- Train set과 Test set의 F1-score 비교
- 특히 불균형 데이터에서는 정확도만 보면 안 되고, F1-score도 확인해야 함.
- Confusion Matrix 확인
- 특정 클래스(특히 소수 클래스)를 너무 과소예측하거나 과대예측하는지 확인.
- Feature Importance 과도한 편향 여부 특정 변수 하나만 너무 중요하게 평가되면 과적합 신호일 수도 있음.
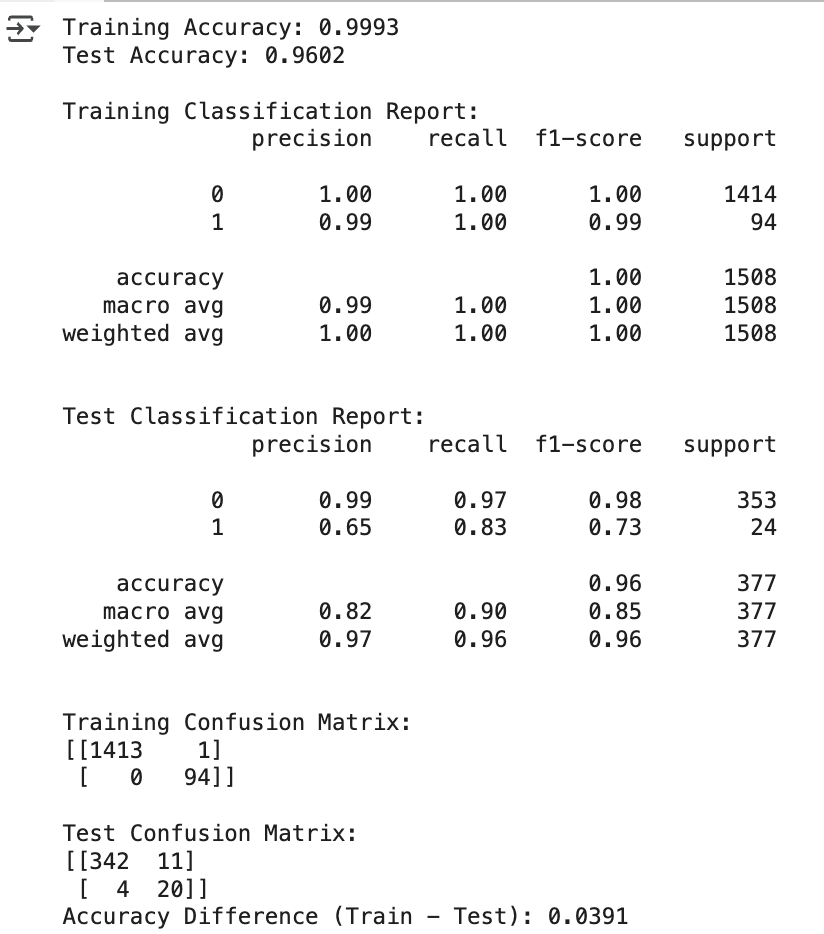
- 과적합 판단 기준
- train_acc > 0.90 이면서 test_acc < 0.75 -> 훈련 정확도가 너무 높고 테스트 성능이 낮음
- train_auc > 0.90 이면서 test_auc < 0.75 -> AUC 차이가 큼
- AUC-ROC 곡선은 다양한 임계값에서 모델의 분류 성능에 대한 측정 그래프
- ROC = 모든 임계값에서 분류 모델의 성능을 보여주는 그래프
- AUC = ROC 곡선의 아래 영역, AUC가 높다는 것(1에 가까운 것)은 클래스를 구별하는 모델의 성능이 훌륭
(11) 과적합 방지
- Hyper Parameter
- 정규화 : 모델에 L1(α), L2(lamda) 정규화를 추가
- Early Stopping : 훈련 시간이 자칫 너무 길어져 너무 많은 학습(과적합)을 하지 않도록 적용
- 모델의 복잡도 감소 : max_depth, learning_rate 조정
- 과적합 방지 후 SMOTE 오버 샘플링으로 다시 모델 최적화
- 이후, 다시 재검정한 결과, 모든 약물에서 '과적합 문제는 심하지 않음' 출력
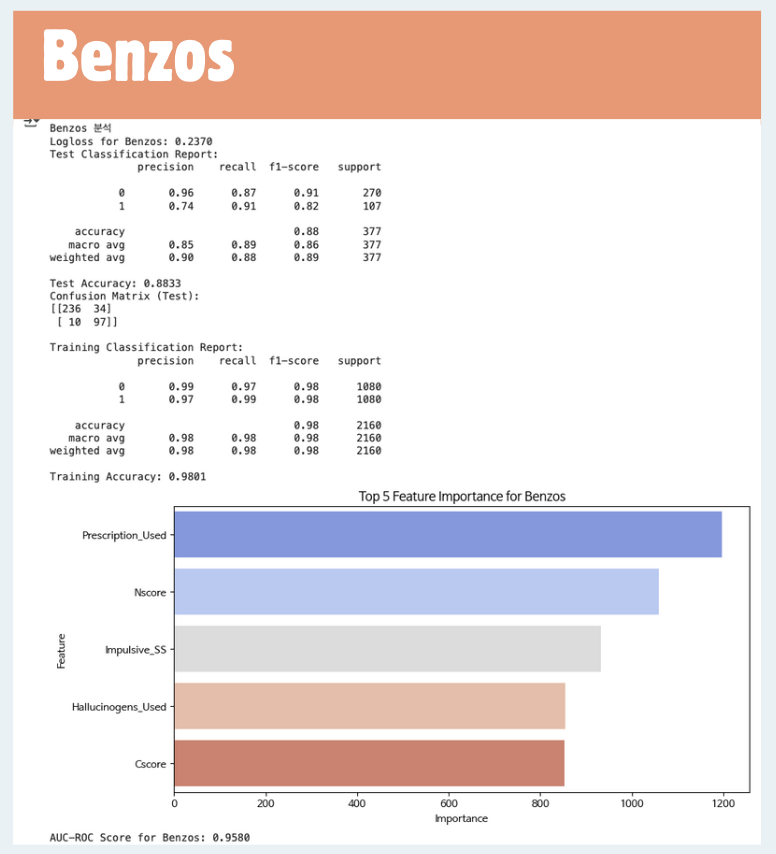
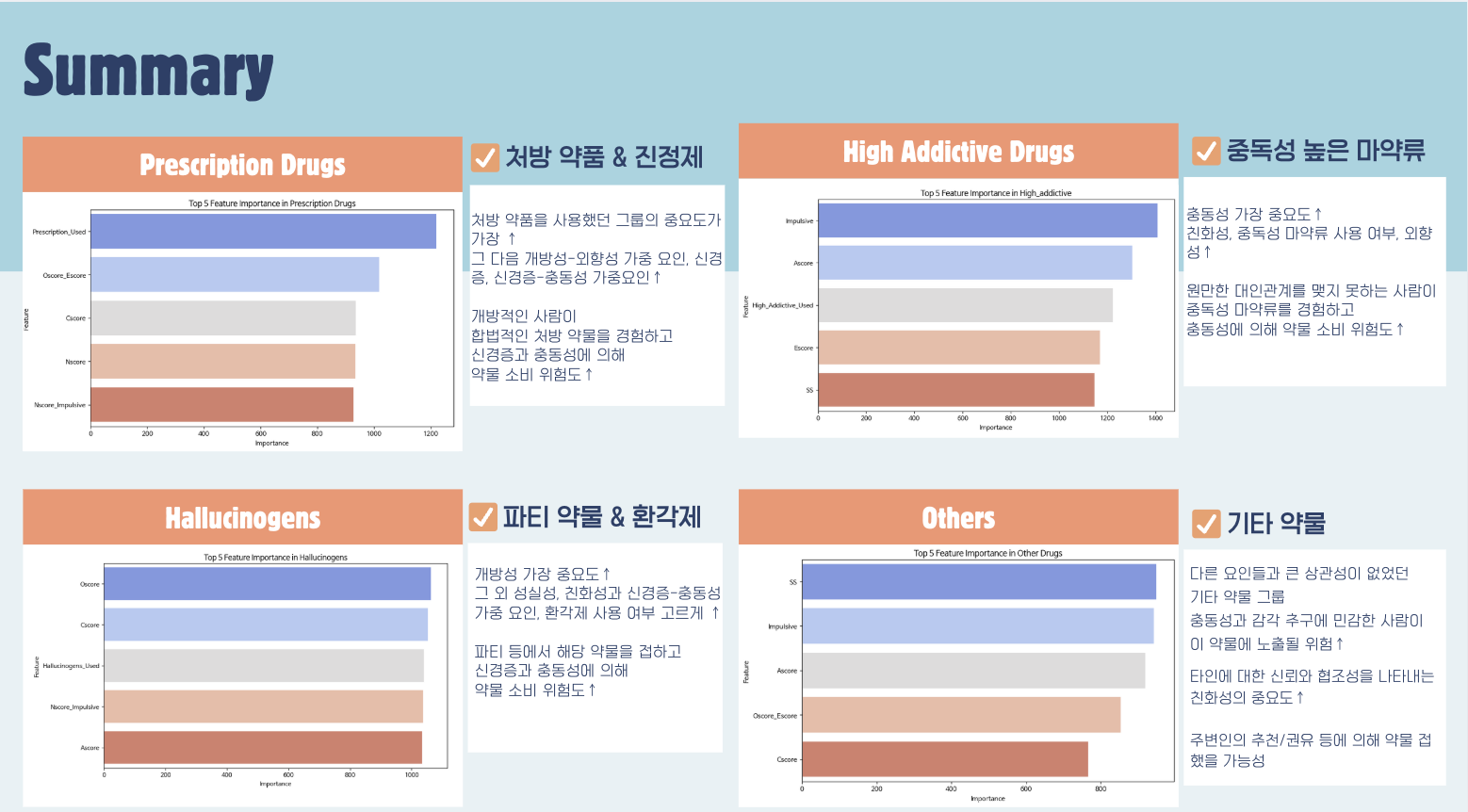
(12) 약물 카테고리별 위험도 예측에 영향을 주는 Feature Importance
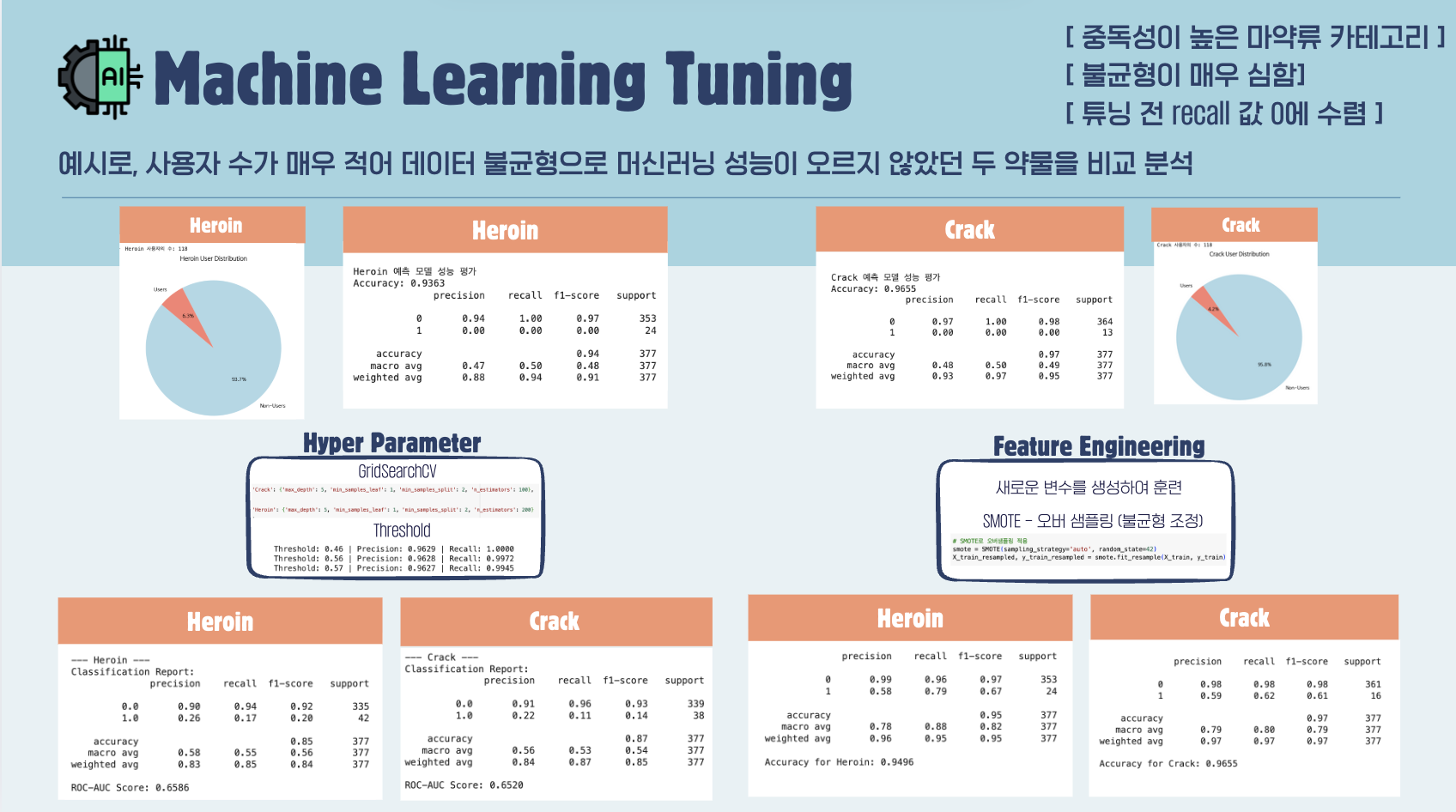
(13) 예시
: 사용자 수가 매우 적어 데이터 불균형으로 머신러닝 성능이 오르지 않았던 두 약물을 비교 분석
[공통점]
- 중독성 높은 마약류 카테고리
- 불균이 매우 심함
- 튜닝 전 재현율(Recall 값) 0에 수렴

(14) 예방 방안 제시
- 데이터 분석 결과, 가설대로 심리적, 사회적 요인이 약물 오남용 위험도와 관련 있었음
- 그 중에서 영향을 주는 요인으로 거의 모든 약물에서 선택된 컬럼은 다른 그룹의 약물 사용 여부나 약물 사용 개수였음
- 즉, 다른 신경 요인도 작용하지만, 이전에 다른 약물을 접해 본 사람이 나중에 다른 약물을 사용할 위험이 높음
- 따라서, 예방이 가장 중요한 약물 중독을 막는 방법
- 그중에서도 충동성이 대부분의 약물 오남용 위험도에 영향을 주었으므로 충동 조절이 좋은 예방 방안
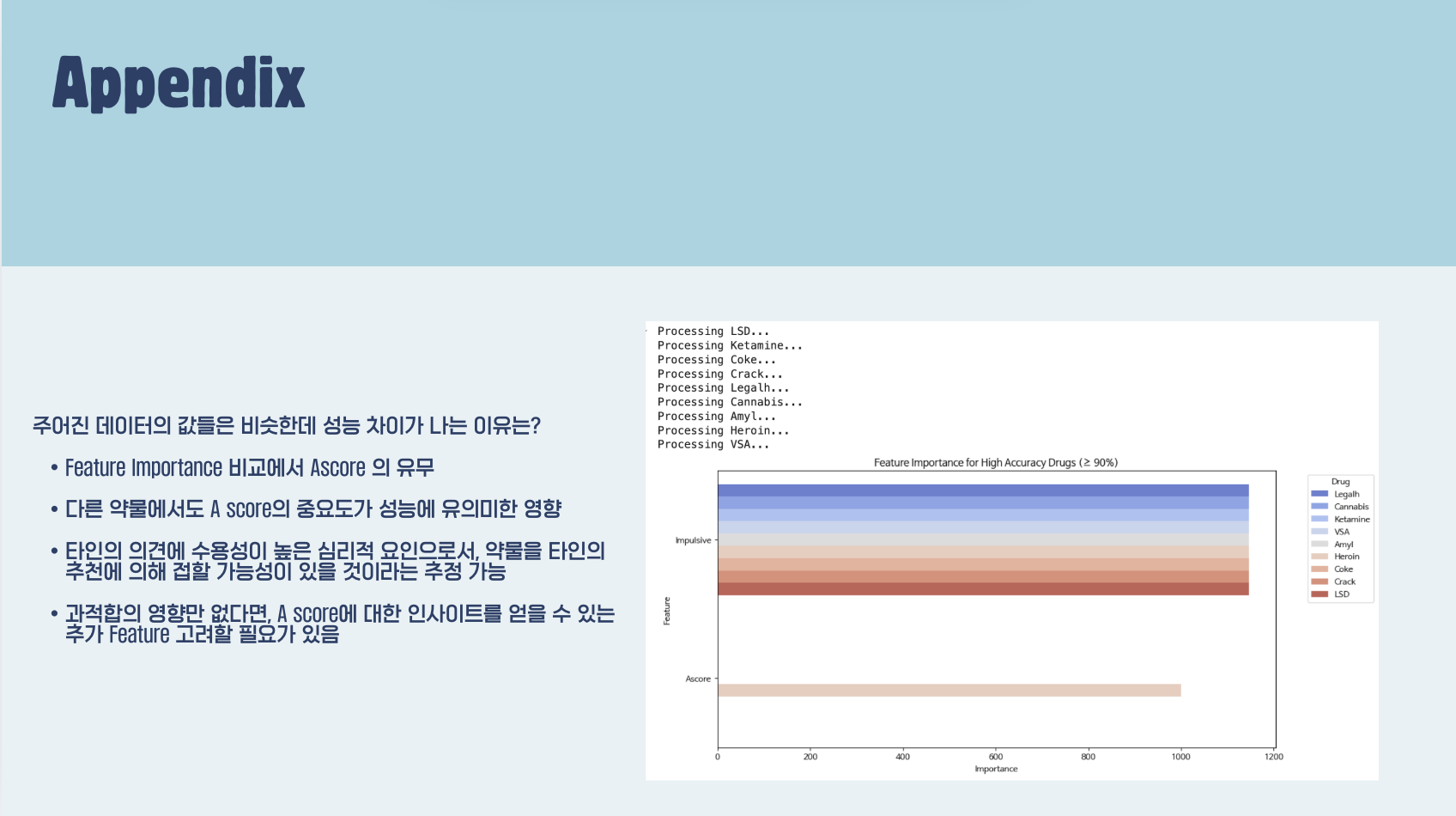
(15) Appendix (추후 분석 제시)
[ 발표회 후 피드백 ]
- 처음 도메인에 대해, 프로젝트 주제에 대해 설명을 해주어서 다음 분석에서 이해가 쉬웠음
- 분석 과정이 논리적이며, 많은 시도를 하려고 한 노력이 보임
- 시각화 자료가 돋보임
- 발표 시간 관계상 중요한 부분 설명이 누락되었는데 중요한 부분은 꼼꼼히 설명하고 지나가도 되는 부분은 자료는 넣되, 꼭 모두 설명할 필요는 없다고 하심
- 발표 마지막에 다른 사람들의 성격 요인을 구글폼 설문지를 통해 받으면 머신러닝을 통해 약물 위험도를 예측하겠다는 페이지를 작성했는데, 이를 먼저 해서 그 결과를 넣었으면 더 좋았을 것이라고 함 (조원들에 대한 것은 결과가 있었지만 중독 위험도가 매우 낮아서 삭제한 내용)
- 변화 수치를 명시적으로 ppt 자료에 추가했으면 보다 이해가 쉬웠을 것
[ 튜터님 피드백 ]

[ 최종 평가 ]
- 일주일동안 총 몇 시간을 잤는지 모를 정도로 시간을 갈아내서 진행한 프로젝트
- 그만큼 아쉬움도 많고 만족감이 높았음
- 머신러닝 성능을 높이는 것은 매우 어려우며, 데이터 불균형에 대해 처리하는 많은 방법을 알게 됨
- 분석 초반에 Feature Engineering을 도입했다면 머신러닝 최적화 시간을 줄이고 추가 분석(heroin - crack이 비슷한 조건이었음에도 성능 평가 지표가 달랐던 이유) 을 진행할 수 있었을텐데.. 라는 아쉬움이 남음
- 그래도 고생했다!